翻译:k0shl
论文地址:http://www.cs.vu.nl/~herbertb/download/papers/anc_ndss17.pdf
作者博客:http://whereisk0shl.top
这个关于侧信道攻击很有意思,也是颠覆一些传统观念的研究,非常值得研究,anc_ndss17.pdf是一个非常好的论文,我对这篇论文进行了翻译,同时也对AnC的源码进行了编译,初步测试,下一步打算仔细研究源码,目前C源码支持x86-64,ARM,以及AMD,平台主要在Linux,VUSec没有公开Javascript代码,因为js的实现可能对于浏览器,adobe系列等等来说还是存在很大危害的,因为这个厂商无法缓解。
但是对C源码的学习有利于我们熟悉这个漏洞,同时也有可能能将其用js实现,我将分享论文的整体框架和其中关于AnC实现部分。
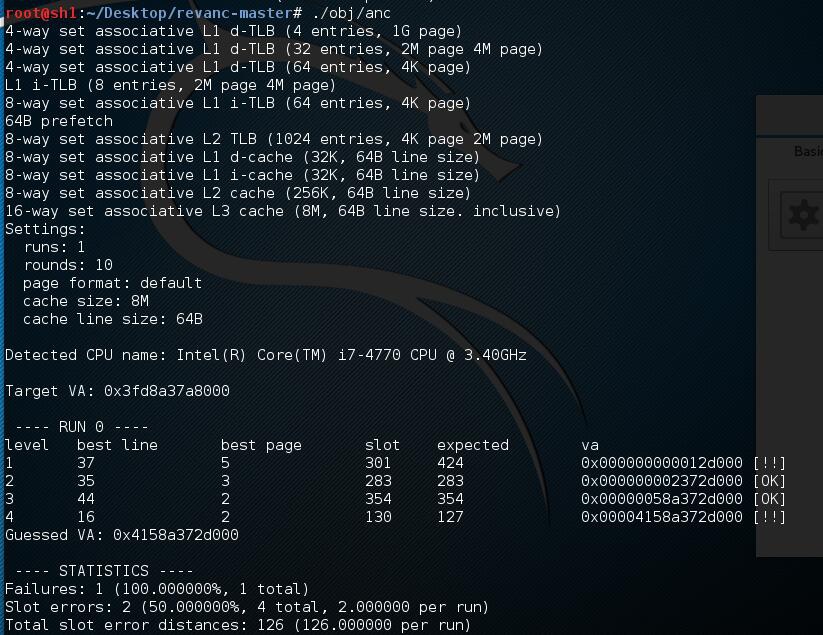
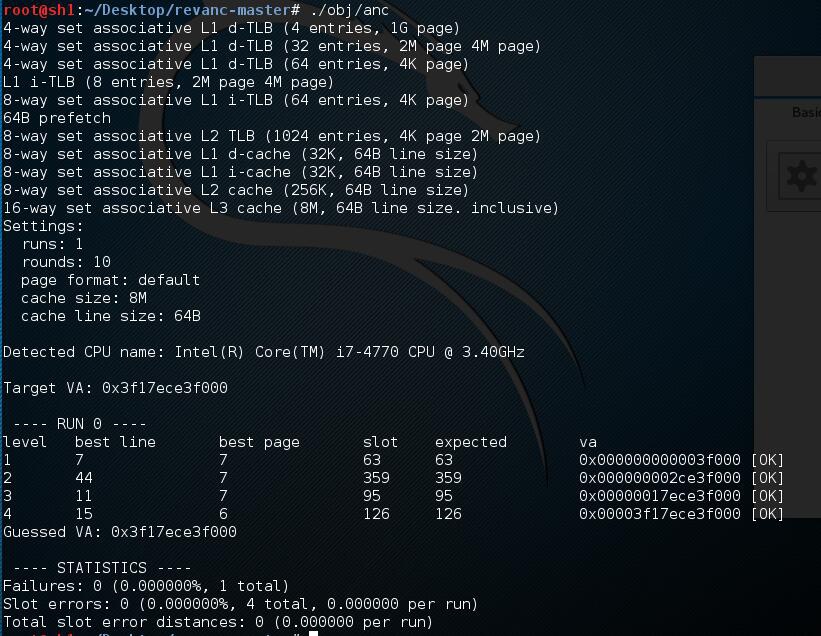
首先我们来看一下整个源码的运行情况,通过测试,这个源码并非每次都能够跑出最后结果,可能受缓存噪声等因素的影响,导致有时候是失败的。
失败的情况:
成功的情况:
这一章我们将讲解在AnC利用过程中碰到的问题,以及如何解决的
我们将会展示AnC成功对浏览器堆的ASLR和火狐浏览器的JIT代码的ASLR进行去随机化,同时和现在的绕过ASLR的方法相比速度更快,需求更低。
首先我们需要了解AnC攻击的基本原理,实际上就是要了解物理地址和虚拟地址的转换,页表级之间的转换规则,相关的内容,在安全客上有一篇关于这个基础原理的翻译。
http://bobao.360.cn/learning/detail/3520.html
对于这种攻击方式的理解,重要的就是下面两幅图:
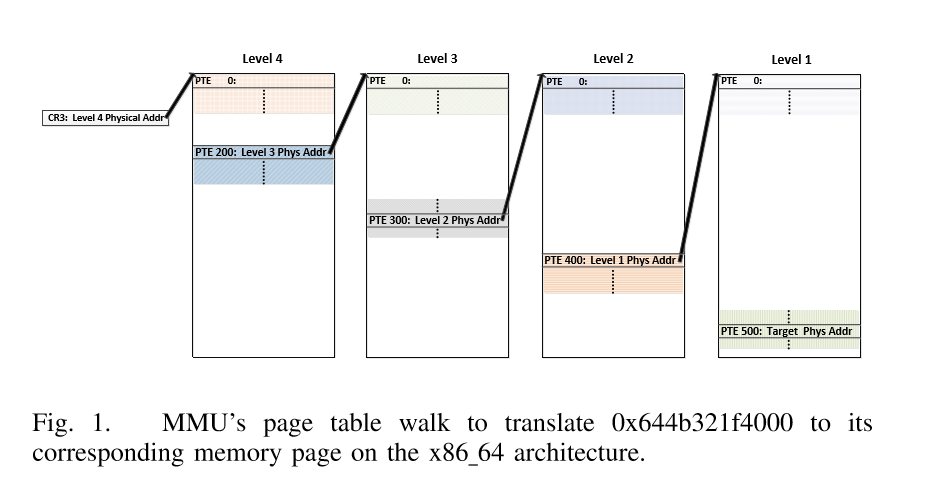
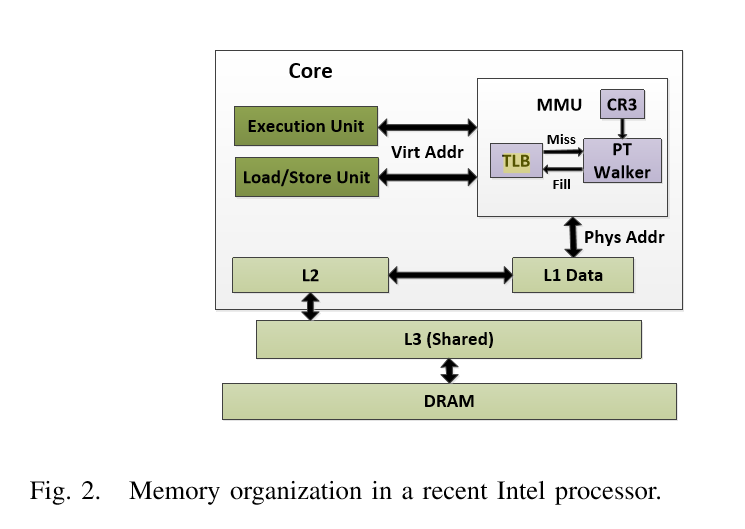
我们重点关注第五章 AnC的实施
安装我们的TTT和SMC计时器,我们现在继续执行第三章D节中描述的AnC。 首先在第五章A节中,我们将展示我们如何在访问目标堆以及的目标JIT区域上执行代码时触发MMU遍历。 然后我们将在第五章的B、C、D节中讨论如何识别存储目标虚拟地址的页表项的页偏移。 在第五章的E、F节中,我们将讲解我们用于观察信号并唯一地识别存储它们的缓存行内的页表项的位置的技术。 在第五章G、H节中,我们讨论了通过激活页表缓存和消除噪声来清理MMU信号的技术。
为了观察CPU缓存上的MMU活动,我们需要确保1)当我们访问目标时,我们知道缓冲区中页偏移,2)我们能够驱逐TLB以触发MMU 在目标内存位置上遍历。 我们讨论如何从堆内存和JIT代码中实现这些目标。
堆:我们使用ArrayBuffer类型来回退我们试图去随机化的堆内存。 ArrayBuffer总是页对齐的,这使我们能够预测目标ArrayBuffer中任何索引的相对页偏移量。 最近Intel处理器有两个级别的TLB。 第一级包括指令TLB(iTLB)和数据TLB(dTLB),而第二级是更大的统一的TLB缓存。 为了同时使用数据TLB和已定义的TLB,我们访问TLB驱逐缓冲区(应该是被驱逐行所保存的缓冲区)中的每个页面,其大小大于已定义的TLB。 我们后面将展示该TLB驱逐缓冲区也可以用于在期望的偏移处驱逐LLC高速缓存集合。
代码:为了分配足够大的JIT代码区域,我们在一个asm.js模块中喷射2的17次方个JavaScript函数。我们可以通过改变由JIT引擎编译的语句的数量来调整这些函数的大小。这些函数的机器码从一个依赖于浏览器的但是在页面中已知的偏移开始,并且在内存中彼此跟随,并且由于我们可以在目标浏览器上预测它们(机器码)的大小,我们知道每个函数从asm.js对象开始位置的偏移。为了最小化这些函数对缓存的影响但不影响它们的大小,我们在所有函数的入口添加一个if语句,以便我们可以不执行函数的逻辑。为了不遮蔽页表缓存行信号,我们的目标是一旦执行就击中单个高速缓存行,但这样做仍然会让功能之间存在大块偏移。为了在执行我们的一个功能时触发页表遍历,我们需要使用iTLB和已定义的TLB。为了使用iTLB,我们使用一个单独的asm.js对象,并执行一些功能,这些功能跨越了超过iTLB大小的页面。为了使用统一的TLB,我们使用我们用于堆的相同的TLB驱逐缓冲区。
正如我们稍后将讨论的,AnC将会在每一轮中观察到一个页偏移量。 这允许我们以不会干扰测量中的页偏移的方式为统一的TLB驱逐缓冲区选择iTLB驱逐函数和页偏移。
AnC的主要思想是我们可以观察MMU的页偏移对LLC的影响。 我们可以为此目的实现两种攻击[49]:PRIME + PROBE或EVICT + TIME。 要实施PRIME + PROBE攻击,我们需要遵循以下几个步骤:
需要较长时间执行的驱逐集可能需要从内存中提取一个(或者多个)项,由于在初始阶段,驱逐集中的条目已经被传入LLC,并且唯一的内存引用(除了TLB驱逐集之外)是目标虚拟地址,因此, 这些“被探测的”驱逐集合中的四个已经托管了用于目标虚拟地址的页表项。 如前所述,这些缓存组唯一地标识每个页表级的页表项偏移的高6位。
然而,这种方法有两个问题。首先,从JavaScript建立最优的LLC驱逐集,PRIME + PROBE是必需的,而最近已经被证明可能需要花费时间,特别是没有精确的计时器。第二,执行PRIME + PROBE攻击可能存在误差,因为我们试图测量的目标将在测量中产生噪声。更确切地说,我们需要在访问目标虚拟地址之前清除TLB。我们可以在启动步骤之前或之后这样做,但是在任一情况下,驱逐TLB将导致MMU执行一些我们不想要的页表遍历。假设我们在主要步骤之前执行TLB驱逐。在执行初期步骤期间访问LLC驱逐集的中间,很有可能会发生许多TLB未命中,导致页表遍历可能在我们不知情的情况下填充已经被引导的缓存集,在探测步骤中会产生许多错误信息。现在假设我们在完成步骤之后执行TLB驱逐的步骤。类似的情况可能会发生:TLB驱逐集中的一些页面将导致页表遍历,导致填充已经被引导的缓存集,并且再次在探测中产生错误信息。
我们使用PRIME + PROBE在最开始实现AnC。 它花费了很长时间来建立最佳驱逐集,并且最终由于噪声很高而不能识别MMU信号。 为了解决这些问题,我们利用我们的目标的独特属性,这样可以不建立最佳驱逐集(第五章C节),从而不会产生大量噪声,并且由于能够控制触发器(MMU的页表遍历),我们可以选择一个更奇特的EVICT+TIME 攻击,允许我们避免PRIME + PROBE(第五章D节)的缺点。
基于缓存的边信道攻击受益于在后端操作之后的缓存状态中可用的整合信息 - 受害者访问的缓存集。 缓存集由颜色(即页颜色)和页(缓存行)偏移量唯一标识。 例如,具有8192个缓存集的LLC中的缓存集可以由(颜色,偏移)元组标识,其中0≤color<128并且0≤offset <64。
ASLR对页偏移中的指针(即,随机化指针)进行编码。 我们可以为页面内的64个缓存行偏移量中的每一个构建一个驱逐集合,驱逐每个集合的该缓存行偏移量的所有颜色。 唯一的问题是不同页表级的页表项可能使用不同的页面颜色,因此,我们就会看到重叠的偏移信号。 但是考虑到我们可以控制观察到的虚拟地址相对于我们的目标虚拟地址的偏移,我们可以控制不同页表级内的页表项的偏移,如第三章D节所述,来解决这个问题。
在下面的描述中,我们的EVICT + TIME攻击不依赖驱逐集的执行时间。 这意味着我们不需要构建最佳驱逐集。 加上ASLR对颜色不可知的事实,我们可以使用任何页面作为驱逐集合的一部分。 不能使用特定的颜色布局方案来分配页表来避免显示这个信号,因为它们都会出现在我们的驱逐集中。 这意味着,在足够大量的内存页的情况下,我们可以在给定页偏移量下从LLC(和L1D和L2)逐出任何页表项,而不依赖于需要很长时间构建的最佳驱逐集。
对加密密钥或窃听的传统侧信道攻击有利于观察整个LLC的状态。 这就是为什么诸如PRIME + PROBE 和FLUSH + RELOAD是允许攻击者观察LLC的整个状态的侧信道攻击的原因。
与这些攻击相比,EVICT + TIME只能在每个测量周期获得关于一个缓存集的信息,与PRIME + PROBE等攻击相比,减少了带宽。 EVICT + TIME进一步做出强有力的假设,即攻击者可以在执行后台运算时观察目标主机的性能。 虽然这些属性经常使EVICT + TIME比其他的缓存攻击差,但是它容易地适用于AnC:AnC不需要高带宽(例如,破解加密密钥),并且它可以监视受害者(即,MMU),因为其执行后台(即,页表遍历)。EVICT + TIME在以下步骤中实现AnC:
EVICT + TIME的第三步触发页表遍历,取决于偏移t的缓存行是否是托管页表项缓存行,操作将需要更长或更短的时间。 EVICT + TIME解决了我们面对PRIME + PROBE的问题:首先,我们不需要创建最佳的LLC驱逐集,因为我们不依赖驱逐集提供信息,其次,LLC驱逐集是用TLB驱逐集,减少由于较少的页表遍历产生的噪声。 更重要的是,这些页表遍历(由于TLB未命中)导致显着减少错误信息,还是因为我们不依赖于探测驱逐集来获得时间信息。
由于这些改进,当在解引用堆地址和执行JIT函数时,在JavaScript中的所有64个可能的缓存行偏移上尝试EVICT + TIME时,可以观察到与目标虚拟地址的页表项对应的缓存行偏移。 我们在第七节提供进一步的评估,但在此之前,我们描述如何可以唯一地标识由EVICT + TIME标识的缓存行内的页表项的偏移量。
在这个阶段,我们已经识别了在不同页表级的页表项的(可能重叠的)缓存行偏移。 对于ASLR仍然保留两个熵源:由于不可能区分哪个缓存行偏移属于哪个页表级,并且缓存行内的页表项的偏移量尚未知道。 我们通过分配一个足够大的缓冲区(在我们的这种情况下是分配一个2G的空间)和访问这个缓冲区中的不同位置来解决这两个熵源,以便对已经分配了缓冲区的虚拟地址去随机化。 我们对PTL1和PTL2去随机化的方法不同于我们对PTL3和PTL4去随机化的额方法。 我们在下面描述这两种技术。
将PTL1和PTL2去随机化:让我们从PTL1的页表项托管目标虚拟地址v的缓存行开始。我们观察到当(可能的)4个高速缓存行之一改变时,因为我们访问v + i×4KB, 1,2,...,8}。 如果其中一个缓存行在i处改变,它立即向我们提供两条信息:改变的缓存行正在托管PTL1的页表项,并且PTL1的v的页表项偏移是8-i。 我们可以执行相同的技术在PTL2对页表项去随机化,但是现在我们需要增加2MB观察PTL2,这样能达到和每次增加4KB的地址相同效果。 作为示例,图5示出了当我们改变PTL1处的页表项的缓存行时AnC观察到的示例MMU活动。
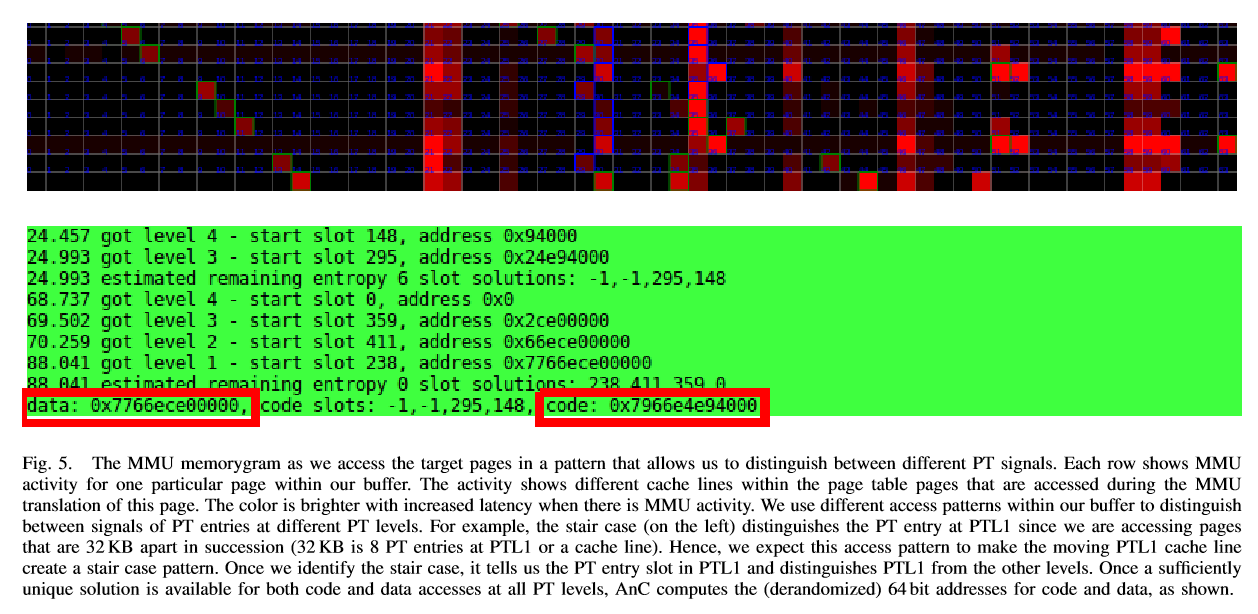
将PTL3和PTL4去随机化:如我们在第三章E节中讨论的,为了使PTL3去随机化,我们在我们的2GB分配内的虚拟地址空间中进行一个的8GB交叉,用来对PTL4去随机化,我们需要在我们分配的空间内进行一个4TB虚拟地址空间交叉。我们依赖于第六节讨论的内存分配器在浏览器中的行为,以确保我们的(许多)分配之一满足这个属性。但是假设我们在PTL3或PTL4改变了缓存行,则我们希望检测和去随机化相对的级别。 注意,在PTL4处交叉的缓存行将不可避免地导致高速缓存行在PTL3处交叉。
记住PTL3上的每个页表项都覆盖1GB的虚拟内存。 因此,如果在PTL3处的缓存行交叉在我们的2GB分配空间内发生,则当交叉正好在缓冲区的中间时,我们的分配可以覆盖两个或三个PTL3页表项。 因为完全在中间的交叉是不可能的,我们考虑具有三个页表项的情况。 三个页表项中的两个或一个在新的缓存行中。 通过在访问分配中的第一页,中间页和最后一页时观察PTL3缓存行,我们可以很容易地区分这两种情况,并完全去随机化PTL3。
只有在PTL3处的缓存行在其相应页表页中的最后时隙中时才发生在PTL4处缓存行交叉。 通过执行类似的技术(即,访问分配中的第一和最后一页),如果观察到页表项缓存行PTE2从最后一个时隙改变到第一时隙,并且另一个页表项缓存行PTE1向前移动一个时隙, 可以结束PTL4交叉并且独特地将PTE2鉴定为PTL3处的页表项并且将PTE1鉴定为PTL4处的页表项。
我们创建了一个简单的求解器,以便对可能的解决方案进行排名,因为我们在2GB分配空间中搜索不同的页面。 我们的求解器为我们的分配缓冲区的第一页的每个页表级假定512个可能的页表项,并且在每个页表级独立于其他级别对解决方案进行排名。
当我们使用我们在第五章E1节和第五章E2节中描述的方法在缓冲区中探索更多页面时,我们的求解程序在其中一个解决方案中获得显着的置信度,或者放弃并开始一个新的2GB分配。 如果在这些页表级存在缓存行交叉,则解决方案会始终对PTL1和PTL2以及PTL3和PTL4进行去随机化。
如第三章B节所述,一些处理器可以将针对不同页表级的翻译结果缓存在其TLB中。 AnC需要驱逐这些缓存以便观察来自所有页表级的MMU信号。 这很简单:我们可以访问一个大于这些缓存大小的缓冲区作为TLB和LLC驱逐的一部分。
例如,Skylake i7-6700K内核可以缓存32个项用于PTL2查找。 假设我们探测在页表页的第i个高速缓存行中是否存在页表活动,访问0 + i×64,2MB + 1×64,4MB + i×64的64MB(即,32×2MB) 64,...,62MB + i×64将驱逐PTL2页表缓存。
虽然我们需要实现这种机制并本地观察所有页表级的信号,我们注意到由于JavaScript运行活动,这些页表缓存在我们的探测期间会被自然驱逐。
实现旁信道攻击的主要问题是噪声。 我们部署了许多对策,以减少噪声。 我们在这里来介绍一下:
随机探测:为了避免硬件预取器引起的错误,我们(仍然)需要探索的可能剩余偏移量中随机选择t(我们驱逐的页偏移量)。这种随机选择也有助于均匀由系统事件引起的局部噪声。
每个偏移量多次采样:为了增加探测的可靠性,我们对每个偏移量进行多次采样(“回合”),并考虑用于决定缓存与存储器访问的中值。 这个简单的策略大大降低了假阳性和假阴性。 对于大规模实验和可视化测量对其他求解参数的影响,请参见第七章C节
对于AnC攻击,假定是无影响的,因为攻击者总是可以使用新的分配重试,我们将在下一节中讨论。 我们使用Chrome和Firefox在第七节中评估AnC攻击的成功率,误报和假否定。
我们实现了两个版本的AnC。 在C中的本机实现,以便研究不具有JavaScript干扰和JavaScriptonly实现的MMU页表遍历活动的行为。
我们将本机版本移植到不同的体系结构和Microsoft Windows 10,以显示第七章D节中介绍的AnC的通用性。 我们的移植努力围绕着实现本地版本的SMC(第四章B节)来准确区分ARM上的缓存和非缓存内存访问,ARM只提供粗粒度(0.5μs)定时机制和处理不同的页表结构。 我们的本地实现代码共1283行。
我们的JavaScript专门在Chrome和Firefox浏览器上工作,目的是展示在第七章中的各种实验中提出的AnC攻击对操作系统的影响。我们需要使用asm.js 调整JavaScript实现,来使测量更快,更可预测。这限制了我们的分配大小最大是2GB。 我们的JavaScript实现用了2370行代码。